Mayorov BLOG
Микросервисные паттерны на реальных примерах
Shared Database | Database per Service
Чтобы освежить в памяти паттерны проектирования распределённых систем, я решил сформулировать к ним небольшие примеры, использующие реальные технологии. В большинстве материалов я встречаю беспредметные описания, которые неопытные разработчики затем неверно интерпретируют. К этому добавляется и тот факт, что многие не видят разницы между микросервисной архитектурой и распределённой системой. Да, микросервисы реализуются как распределённая система, но не каждая распределённая система использует микросервисы (паттерны проектирования распределённых систем имеют более высокий уровень абстракции).
Эта статья — первая часть цикла моих заметок с примерами именно микросервисных паттернов. Я постараюсь избегать громоздких формулировок, исторических справок и сложных диаграмм (хотя, спойлер: всё-таки добавил диаграммы). Только короткое описание и пример реального веб-проекта с микросервисной архитектурой.
Основой для материала послужили статьи Криса Ричардсона, его книга «Microservices Patterns» и сайт microservices.io. Хоть мне и нравится структура и описание микросервисных паттернов у Ричардсона, это не означает, что наши мнения совпадают во всём. Я часто буду добавлять свои комментарии. Например, я не согласен с его радикальной позицией, что микросервисы — это, по сути, серебряная пуля для любого среднего или крупного проекта, а все монолиты обязательно нужно «распилить», ведь они якобы не поддерживаемы и не расширяемы (прим.: не прямая цитата).
Наверное, когда у тебя свой консалтинг по распиливанию монолитов, легче привлекать клиентов 🤔.
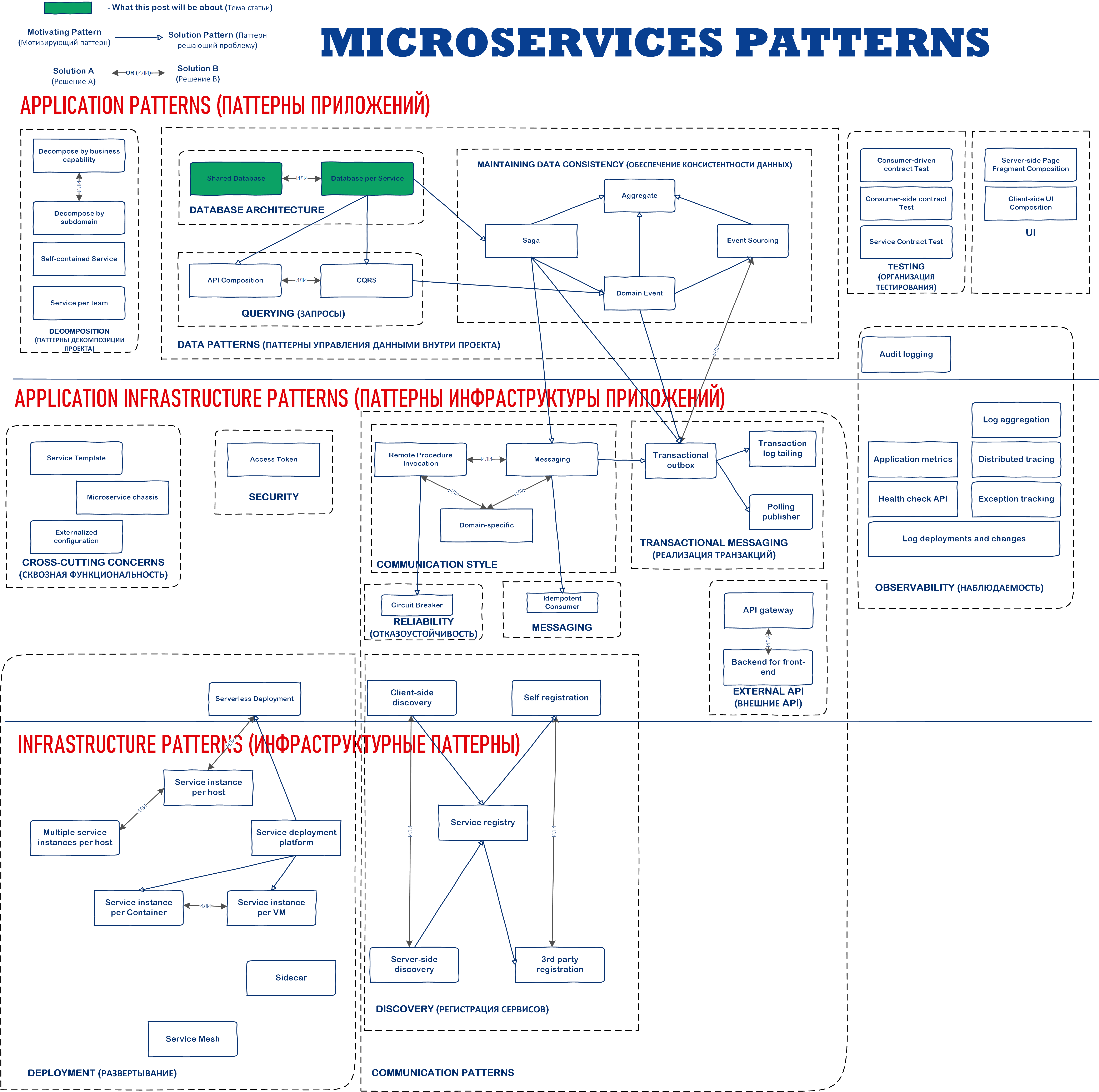
Рассмотрите внимательнее эту диаграмму - зеленым в каждой новой статье будут отмечены паттерны, о которых пойдет речь. Оригинал: Chris Richardson
Считаю, что 90% современных приложений не нуждаются в микросервисной архитектуре и их можно грамотно реализовать в виде модульного монолита. Но если вы разрабатываете что-то из оставшихся 10%, думаю, эти заметки вам помогут.
Ну что ж, начнём с паттернов “Database Architecture”.
Паттерны «Единая база данных» (Shared Database) и «По базе данных на сервис» (Database per Service)
Шаблоны из слоя «Паттерны приложений» проще всего описывать на конкретных примерах, ведь они всегда касаются конкретной реализации. Итак, вы планируете архитектуру проекта. Какой может быть сетап баз данных?
Есть две крайности:
- У вас одна большая база данных с множеством таблиц, к которой подключаются все сервисы.
- Плюсы: удобно джойнить данные, и, если что-то требуется, не нужно стучаться к соседнему сервису.
- У каждого приложения — своё место для хранения данных.
- Плюсы: слабая связность и большая гибкость в реализации.
Каждая из этих крайностей реализует свой паттерн:
- первая — «Единая база данных» (Shared Database),
- вторая — «По базе данных на сервис» (Database per Service).
Естественно, в глобальном смысле общая база данных в микросервисной архитектуре — это антипаттерн. Она усложняет независимое масштабирование, обновление и отладку сервисов. Например, одно изменение в схеме может «положить» сразу несколько приложений.
Сразу же возникает вопрос: если shared database — антипаттерн, почему он отражён в нашей диаграмме? Дело в том, что подход к взаимодействию с базой нужно рассматривать с разных точек зрения и в разных масштабах. Если у вас одна БД на 50 микросервисов — это явно антипаттерн, так как появляется сильная связность и проблемы с масштабированием. Но если одна база обслуживает всего пару-тройку сервисов, при этом один из них отвечает за запись в мастер-базу, а другие — только читают с её реплик, то такой подход можно считать адекватным компромиссом.
Кстати, обратите внимание, что если каждый отдельный сервис взаимодействует с отдельной репликой одной и той же базы, это всё равно не «database per service», а по-прежнему «shared database», просто с распределением нагрузок между репликами.
 Предположим, у нас есть сервис, который напрямую работает с
заказами пользователей (добавляет их, изменяет, отменяет), и есть аналитический дашборд
для этих заказов, где выполняются преимущественно операции чтения. Вполне приемлемо (и
ещё раз — приемлемо) подключить их к одной базе данных, и
делать запись в мастер из сервиса заказов, а чтение аналитикой и снова сервисом заказов
с реплик. К тому
же это не отменяет наличия у аналитики ещё одной собственной базы данных для
хранения промежуточных результатов и расчётов.
Предположим, у нас есть сервис, который напрямую работает с
заказами пользователей (добавляет их, изменяет, отменяет), и есть аналитический дашборд
для этих заказов, где выполняются преимущественно операции чтения. Вполне приемлемо (и
ещё раз — приемлемо) подключить их к одной базе данных, и
делать запись в мастер из сервиса заказов, а чтение аналитикой и снова сервисом заказов
с реплик. К тому
же это не отменяет наличия у аналитики ещё одной собственной базы данных для
хранения промежуточных результатов и расчётов.

Преимущества Shared Database:
- Единая база данных проще в эксплуатации.
- Легче поддерживать консистентность данных.
Недостатки Shared Database:
- Связанность во время выполнения. Все сервисы обращаются к одной и той же базе данных, что может привести к взаимным помехам.
- Одна база данных может не удовлетворять требованиям всех сервисов к хранению и доступу к данным.
А теперь представьте стартап в сфере ритейла. Ваша команда разделена на несколько групп: одна работает над сервисом управления заказами, другая — над рекомендациями, третья — над поиском. Разные сервисы имеют разные требования к хранению данных. Для одной команды оптимальны реляционные базы данных, для другой — колоночные, а третья не обойдётся без векторных.
Пример:
- Сервис управления заказами использует реляционную базу данных PostgreSQL для хранения детальной информации о заказах.
- Команда рекомендаций применяет документно-ориентированную NoSQL-базу данных MongoDB для быстрой работы с неструктурированными данными о предпочтениях пользователей.
- В команде поиска используется ElasticSearch.

Благодаря такому разделению ответственности каждый сервис развивается независимо и использует наиболее подходящую технологию для своих задач. Это ускоряет разработку и повышает производительность всей системы. Когда одной команде понадобится провести манипуляции с данными в БД другой, она просто использует API, которое должно быть предоставлено (REST или брокеры сообщений).
Преимущества Database per Service:
- Изменения в базе данных одного сервиса не влияют на другие.
- Каждый сервис может использовать наиболее подходящую базу данных.
Недостатки Database per Service:
- Сложность реализации межсервисных транзакций и запросов.
- Управление множеством баз данных требует дополнительных усилий.
В следующей статье я расскажу про паттерны API Composition и CQRS